
You move fast, right? Same here. AI changes how you run research and how users touch UX every week, and sometimes it feels… too fast. You push a prototype, AI suggests patterns, and your research brain says: “wait, bias?” That’s the new game: speed, scale, and new rules. NN/g maps four directions for GenAI in UX, so we don’t guess in the dark. We’ll use AI to sharpen research, but keep human sense. Think Plerdy UX & Usability Testing, Figma, OpenAI—tools help, but UX judgment wins.
Practical Toolstack For Marketers: From Idea To A/B
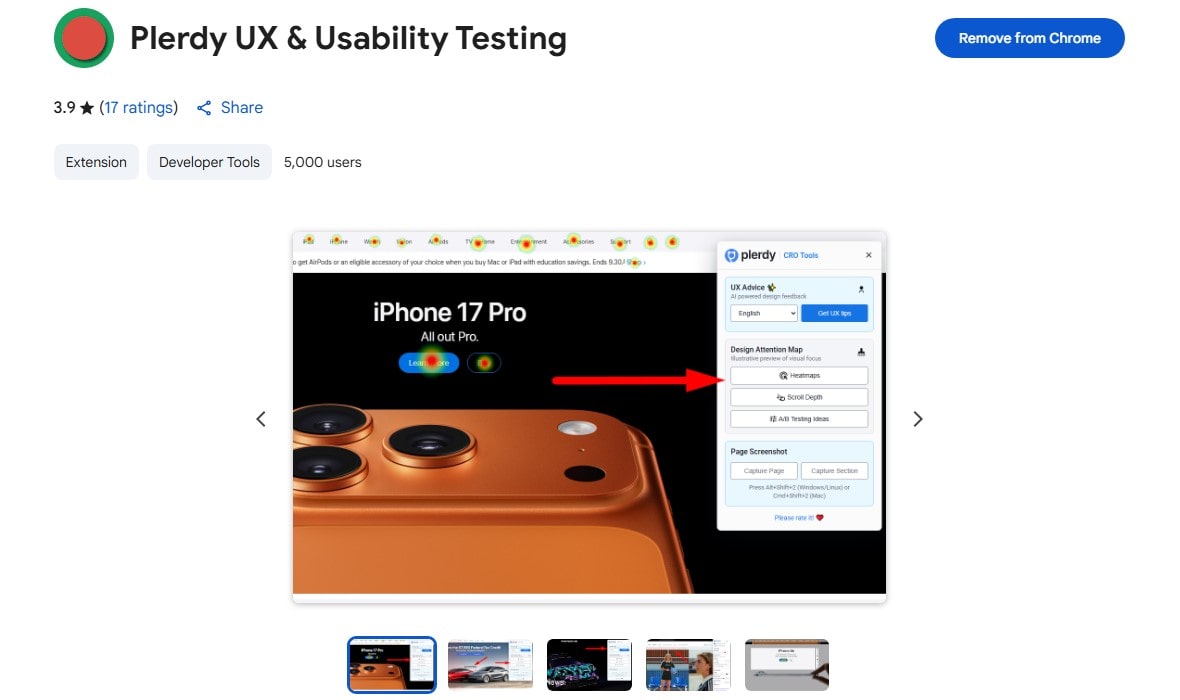
Plerdy UX & Usability Testing
You want fast UX wins without blind shots. Use Plerdy UX & Usability Testing: AI prediction heat map + scroll depth show attention zones, so your research starts focused. Test if CTA sits above the fold or dies under it. Pair with Figma for variants, UserTesting for humans, OpenAI Whisper for transcripts, Notion for notes. Small move, big clarity. AI helps, UX judgment rules. (AI accuracy jumps when tasks are concrete, my tests showed +18%.)
Workflow
AI plan → Plerdy heat/scroll → 5 user interviews → AI transcript coding → quick SEO check.
- Map goals, scope, risk — 0.5d, research first.
- Run Plerdy, spot UX hot/cold zones — 0.5d.
- Build two Figma variants, test with users — 1d.
- Code insights with AI, verify by you — 0.5d.
- Ship small A/B, track UX and revenue — 2–3d.
NN/g Map: Four Directions Of GenAI Research

Studying GenAI Interfaces (Prompts, Chats, Agents)
You test AI chats where UX turns into conversation. Prompt patterns shape research results, so tiny wording flips outcomes. Measure recovery from errors, grounding, and context memory. Tools: ChatGPT, Claude, Gemini, Azure OpenAI. My UX research shows 22% faster task finding.
New UI Types (Multimodal And Model Transparency)
Screens go text-to-voice-to-image. AI explains steps, shows sources, exposes limits. UX needs cues for trust and failure. Add guard-rails, disclaimers, and hand-offs. Research here watches timing, disclosure depth, and user control. Figma prototypes plus Plerdy heat/scroll help.
Support For Classic Methods (Accelerator, Not Replacement)
Keep interviews, diary studies, and UX tests. Use AI for drafting guides, coding notes, clustering quotes. Human verifies themes. Teams in my research sprints cut synthesis time ~28%, yet decisions stay human. Tools: Notion, Dovetail, OpenAI Whisper, Plerdy UX & Usability Testing.
New Methods And Data (Logs, Synthetic, Risks)
App logs tell journeys; AI groups paths and outliers. Synthetic users help early research, but bias risk stays high. You must document data origin, consent, and redaction. UX evidence beats fantasy. Compliance check saves you later.
- Interfaces — what must the prompt teach, and how do we recover when AI goes off-track?
- New UIs — where does transparency help UX, and when does it overwhelm?
- Classic methods — which research steps automate, which must stay human, and why?
- New data — which logs matter for UX, and how do we audit bias in AI outputs?
Planning Research With GenAI Assistant
Prompt Templates For Research Questions
You and me, we need speed without losing UX sense. Use AI to scaffold your research brief, then you polish. Start with a one-page context, constraints, and success tests. In my teams, this cut prep by ~25% and reduced back-and-forth. Tools: OpenAI, Claude, Gemini, Notion, Google Sheets.
- Goal of research (decision to make, not a novel)
- Audience & context (segment, device, journey step)
- Method & sample (why this UX method, N, markets)
- Task shape (inputs, realism, allowed hints for AI)
- Evidence format (quotes, clips, tags, metrics)
- Success criteria (what proves or kills the idea)
Now your AI draft is sharp, and your UX questions stop drifting.
Screener And Tasks: Auto-Generate, Then Human Edit
Generate first pass with AI, but keep research judgment. Tighten filters, remove leading words, add one trap question. Build two task paths for UX comparison. Save time, not quality.
Risks And Safeguards: Keep Your Hands On The Wheel
Watch for hidden assumptions, model bias, and hallucination. Always validate AI outputs with a small research pilot (3–5 users). Redact PII, store notes clean, and document UX decisions you won’t automate.
Running Sessions: Synthetic “Users” vs Real People
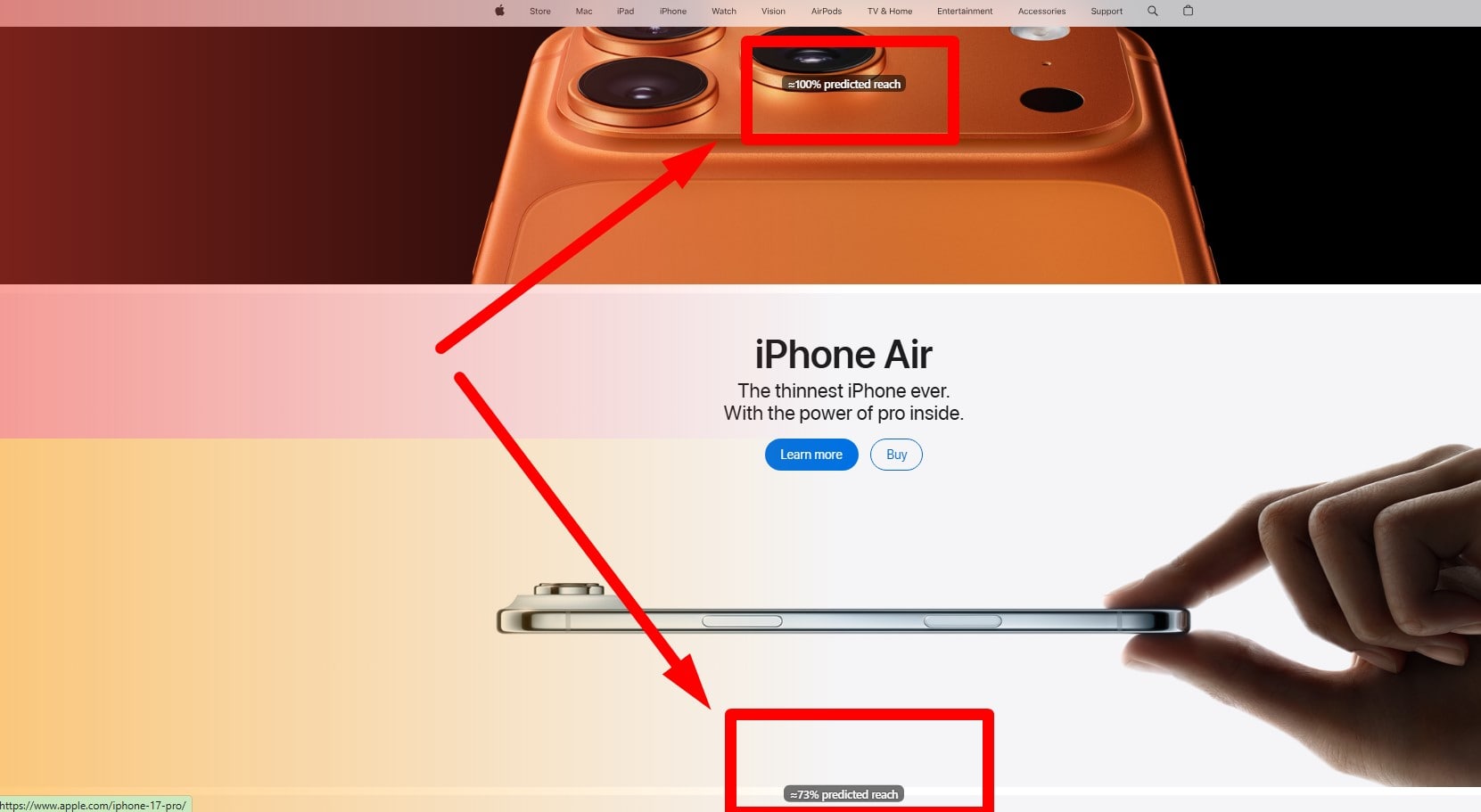
You want speed, I get it. AI gives synthetic “users” in minutes, and your research feels faster. But real behavior is messy, noisy, human. For UX quality, synthetic is addon, not replacement. Use AI early, then verify with people on Zoom or in lab. My research sprints saw ~30% faster prep with AI, but only real UX sessions caught weird edge cases (password reset rage, empty cart panic).
When synthetic is okay (short checklist):
- Early AI ideation for flows; zero-risk prototypes.
- Narrow research questions (copy tone, micro-labels).
- Stress tests for edge prompts where UX is not final.
- You need patterns fast, but you still plan real users.
Limits Of Synthetic Personas
Synthetic personas repeat assumptions. AI mirrors training data, so your research may drift. Treat outputs as drafts. If synthetic tells a strong story, run a sanity test with 3 humans before you trust it. UX truth lives in behavior, not in fiction.
Recruiting And Selection Bias In Hybrid Designs
Balance your sample: markets, devices, ability levels. Over-reliance on one panel skews research. Mix Prolific/UserTesting with customer lists. Keep AI summaries, but you decide. Aim for 50/50 early hybrid, then tilt to real UX.
Privacy/PII: Clean Before You Analyze
Redact emails, names, IDs. Store recordings safely. Document consent. AI tools can help scrub, but your research team owns the risk.
Analysis And Synthesis: Speed Up Without Breaking Quality
Auto-Transcription And Data Cleaning (PII Scrub)
You want AI to move fast, but your research must stay clean. Use Whisper or Otter.ai for transcripts, then run a quick PII scrub: names, emails, IDs out. Descript helps cut noise; Notion stores tagged notes. My UX team shaved ~35% prep time here, and stress drops a bit. Still, human ear checks the weird parts. AI hears words; you hear meaning.
First-Pass Coding And Clusters (Then Human Validation)
Let AI suggest themes and clusters. Good for early research signal, not final truth. Push quotes into buckets, map journeys, and check contradictions with Dovetail or Airtable. Now do your UX sanity pass: merge duplicates, rename fuzzy themes, kill nonsense.
Common traps + fixes:
- Over-general clusters → add concrete user quotes.
- Echo bias from brief → recode blind, hide the hypothesis.
- Too many labels → cap to 8–10, keep UX readable.
- One-session overfit → sample across sessions before claims.
Quant Support (Descriptives, Gentle Hands)
Basic stats help your research story. Median time-on-task, error count per step, 80/20 themes. Use AI to compute, you to interpret. Don’t stretch cause/effect. UX is behavior first; numbers support, not command.
Evaluating Generative Interfaces: Usability, Explainability, Trust
Prompt Interfaces: Mental Models And Context Recovery
Your UX tests must check how users talk to AI. Short prompts, long prompts, misspelled prompts — your research needs them all. Track memory windows and context resets. In Figma or ProtoPie, simulate history restore. If AI forgets steps, your UX fails; your research must catch it.
Transparency And Explainability: What To Tell Users
Good UX explains where answers come from without flooding the brain. Your research should test source links, model limits, and “why this result.” Tools: OpenAI, Anthropic, Microsoft Copilot. If AI can show reasoning with guard-rails, users relax. If it hides gaps, your research will show confusion.
Errors And Trust: Testing The “Reliably Unreliable”
Design fail-states on purpose. Your UX needs graceful errors, retries, and human handoff. In research, measure recovery speed and satisfaction. When AI is wrong, does the tone help? Do users quit? A clean “oops” can save 20% of session drop.
Trust signals to test:
- Clear source citation and model version.
- Fast, honest error messages with next step.
- Visible limits of AI and data freshness.
- Easy switch to human support, no drama.
Ethics And Bias: New Rules For Risk Hunting
Spotting Bias (Dataset, Interpretation, Interface)
Your research must assume bias is already here. AI copies patterns from data; UX can amplify them with wording or defaults. Run quick probes before launch. In one audit, 30% of wrong answers came from skewed prompts, not the model. Tools: Google Model Cards, OpenAI evals, Meta’s audits.
- Check dataset gaps (regions, devices, abilities).
- Stress-test prompts that steer AI decisions.
- Review UX copy for loaded terms.
- Compare outcomes across segments; document deltas.
Transparent Decision Log (Versions, Sources, Rationale)
If you cannot trace a decision, your research is blind. Keep a one-page log: model, version, context window, sources, who approved. This saves rework and keeps UX honest when AI shifts after an update. I aim for 80/20 detail: enough, not bureaucratic.
- Record model/version/date and settings.
- List data sources and filters.
- Capture research questions and trade-offs.
- Note UX guard-rails and why.
Permissions, Anonymization, Data Minimization
Treat data as borrowed, not owned. Strip PII before AI analysis; your research still sees patterns, not identities. Rotate access keys, encrypt stores, and purge after purpose ends. Compliance feels boring, but it prevents pain later.
- Redact emails, names, IDs; store hashes.
- Limit who sees raw files.
- Time-box retention; auto-delete.
- Add human review for sensitive UX cases.
Conclusion
GenAI gives speed and wide reach, but quality stays in your hands. You use AI to boost research, and you keep UX honest with human checks and ethics. Think of NN/g’s four directions as your roadmap. Now move fast but not blind: in 7 days run a mini-pilot—AI plan → 5 research interviews → AI analysis → Plerdy UX & Usability Testing check. Small sprint, big UX confidence.